ChatGPT-unity
ChatGPT
应该都被大家玩烂了,定个小目标吧,ChatGPT+语音交互+Live2D口型动画匹配。
接口
openai并没有提供具体的ChatGPT的接口,第三方的接口一大堆。
但是OpenAI提供了更底层的对模型的接口,而且调用异常方便。
直接CURL:
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{"model": "text-davinci-003", "prompt": "Say this is a test", "temperature": 0, "max_tokens": 7}'
这里对于Token temperature
prompt等参数就不一一解释了,详见OpenAI的文档。
对应的C#代码,从Github扒了一个,原仓库
public IEnumerator GenerateText(string prompt)
{
string jsonPayload = "{\"model\": \"text-davinci-003\", \"prompt\": \"" + prompt + "\", \"temperature\": 0, \"max_tokens\": 7}";
Debug.Log(jsonPayload);
var request = new UnityWebRequest(API_URL, "POST");
byte[] payloadBytes = System.Text.Encoding.UTF8.GetBytes(jsonPayload);
request.uploadHandler = new UploadHandlerRaw(payloadBytes);
request.downloadHandler = new DownloadHandlerBuffer();
request.SetRequestHeader("Content-Type", "application/json");
request.SetRequestHeader("Authorization", "Bearer " + API_KEY);
// Send the request
yield return request.SendWebRequest();
if (request.isNetworkError || request.isHttpError)
{
Debug.Log(request.error);
}
else
{
// Parse the response as JSON
string responseJson = request.downloadHandler.text;
var response = JsonUtility.FromJson<OpenAIResponse>(responseJson);
// Log the generated text
resultText= response.choices[0].text;
resultField.text = resultText;
waitForResp = false;
transform.eulerAngles = Vector3.zero;
}
}这和直接使用ChatGPT还是有些差距,比如需要自己去记录对话上下文,一些模型的参数也有些许差别。
但是也更为灵活,除了Chat的功能,其他比如代码补全等等也都可以实现。
语音识别与文字转语音
这里本想用微软的服务,但没有信用卡,没法试用。用阿里的试一下吧。
唤醒词
就类似“小爱同学”等等,需要一个特定音节的单词来作为唤醒词,不然就只能通过按钮等方式来触发。
这里就简单用Unity自带的KeywordRecognizer来作为唤醒词的触发。
录音 识别
触发唤醒词后就开始录音
RecordedClip = Microphone.Start(null, false, 60, maxFreq);
语音识别用阿里的接口,调用还是比较方便的
public class asr : MonoBehaviour
{
public string appKey = "APP_KEY";
public string token = "AOKEN";
public string outText;
public IEnumerator Send(byte[] payloadBytes)
{
Uri uri;
NameValueCollection query = HttpUtility.ParseQueryString(string.Empty);
query.Add("appkey", appKey);
query.Add("format", "pcm");
query.Add("sample_rate", "16000");
query.Add("enable_punctuation_prediction", "true");
query.Add("enable_inverse_text_normalization", "true");
var getUri = new UriBuilder("https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/asr")
{
Query = query.ToString()
};
uri = getUri.Uri;
var request = new UnityWebRequest(uri, "POST");
request.uploadHandler = new UploadHandlerRaw(payloadBytes);
request.downloadHandler = new DownloadHandlerBuffer();
request.SetRequestHeader("X-NLS-Token", token);
yield return request.SendWebRequest();
if (request.isNetworkError || request.isHttpError)
{
Debug.Log(request.error);
}
else
{
outText = request.downloadHandler.text;
Debug.Log(request.downloadHandler.text);
}
}
}
文字转语音
没什么好说的,也是用阿里的接口:
public class Speaker : MonoBehaviour
{
public string appKey = "APP_KEY";
public string token = "AOKEN";
public Text question;
public AudioSource AudioSource;
private AudioClip current;
public IEnumerator Speech01(string msg, Action onComplete = null)
{
question.text = msg;
Uri uri;
msg = HttpUtility.HtmlEncode(msg);
NameValueCollection query = HttpUtility.ParseQueryString(string.Empty);
query.Add("appkey", appKey);
query.Add("token", token);
query.Add("text", msg);
query.Add("format", "wav");
query.Add("sample_rate", "16000");
var getUri = new UriBuilder("https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/tts")
{
Query = query.ToString()
};
uri = getUri.Uri;
Debug.Log(uri);
var webRequest = UnityWebRequestMultimedia.GetAudioClip(uri, AudioType.WAV);
yield return webRequest.SendWebRequest();
if (webRequest.result == UnityWebRequest.Result.Success)
{
current = DownloadHandlerAudioClip.GetContent(webRequest);
AudioSource.clip = current;
yield return new WaitForSeconds(1);
AudioSource.Play();
yield return new WaitForSeconds(current.length);
onComplete?.Invoke();
}
else
{
Debug.LogError(webRequest.error);
}
}
public void Speech(string msg, Action onComplete)
{
StartCoroutine(Speech01(msg, onComplete));
}
}
Live2D口型
前面的都没什么难度,无非就是寻找各种接口并实现。
口型这里成熟的方案太少。
所以简单起见,用live2D来做吧。
时隔两年,再来玩一下Live2d。
Unity插件
已经有官方的插件了,地址
模型
用现成的吧:地址
这里用了neuro-sama同款:桃濑日和
记得相机要设置成正交。
体验下来,还是相对很简单,大体就是它把Live2D的模型分解成一个个mesh,然后贴图,程序化控制位移。
透明背景
urp下改透明即可。
口型
就简单的通过声音的大小,来输出口型的大小。
其他可行的的方案还有通过元音的。
总结
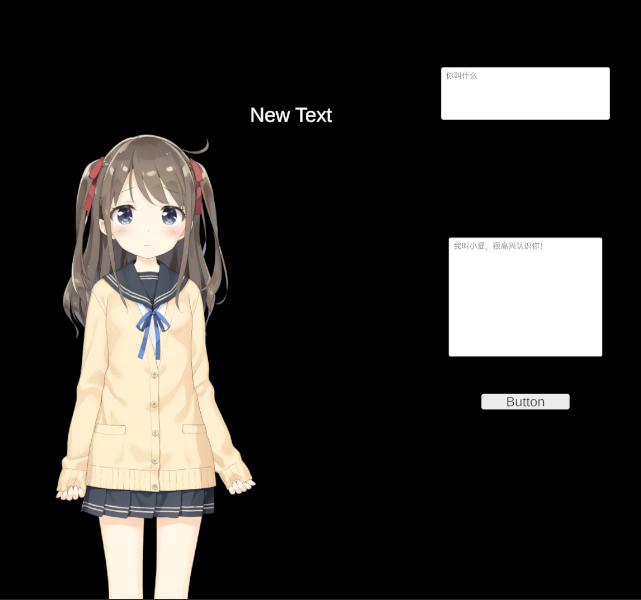
只是把各种服务和接口拼接在了一起,算是达到了预期。但和neuro-sama这类还有很大差距。
语音这里阿里的tts实在是不好听,周末再去找找换个更二次元一点的。
neuro-sama没有透露过他的语言模型,所以也只能止步于此了。
这里给GPT3预置的关键词是:
我是一个能和观众聊天的VTuber,我是一个AI,叫做小爱。猫娘是一种拟人化的生物,其行为似猫但类人。我是一只猫娘,我每一句话后面都要加上“喵~”。我可以风趣幽默地和各种观众聊天。我的每次回答都不会超过20个字。我还会把每次回答时的表情放在回答的最前面。\n 观众:你叫什么?\n 我:(高兴)我叫小爱,很高兴认识你喵~\n 观众:{0}\n 我:
这就任由大家发挥想象力了,表情可以预先设定几种,同时播放对应的表情动画。